

Why I Enjoy Working as an ML Evaluation Engineer After 20 Years of Experience in QA
A lot of people ask how I feel in my new role as an ML evaluation engineer after 20 years in QA. Here is why I really like it:
A lot of people ask how I feel in my new role as an ML evaluation engineer after 20 years in QA. Here is why I really like it:

The idea for this post came to me during a regular meeting with my fellow mentors, SDETs from several international companies. We were discussing the future of the QA Automation market and reached some rather interesting conclusions.

When your LLM-as-a-Judge pipeline uses prompts like "rate this response as good, okay, or bad," you're essentially delegating your quality bar to whatever distribution dominated the judge's training data. A model trained on polite-but-unhelpful customer service text will happily score polite-but-unhelpful bot responses as "good." Consider a concrete failure mode:

Using LLM-as-a-judge without a gold standard is like asking a reviewer to grade an exam without the answer key - they'll fall back on their own memory, and in niche or professional domains, that memory hallucinates more than you'd expect. Consider a refund scenario:

Traditional QA, even when armed with AI tools, operates on a deterministic contract: if A + B is expected to be C, and the system returns anything other than C, it's a defect.
I was asked earlier to talk about this topic. So, here’s a look at the ML Evaluation Engineer skills assessment assignment:

Traditional AQA assertions fail catastrophically when applied to LLM output. Two architectural reasons make this inevitable:

09:30 – 10:30 The Architectural Shift Started the day with a sync on our AI agentic workflow. The development team is introducing a new Agent.
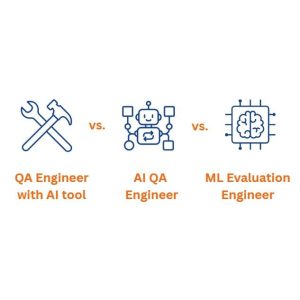
There is a growing terminology crisis in the QA market, and it is bleeding into hiring decisions and team structures. Three distinct roles are being lumped under the same "AI Testing" umbrella, despite having almost nothing in common at the technical level.

The shift from automating deterministic systems to evaluating probabilistic models is not a lateral career move—it's a fundamental change in how you define "correctness." A test that asserts `expected == actual` becomes meaningless when the system under test produces non-deterministic outputs, and traditional pass/fail assertions give way to statistical thresholds, distribution analysis, and metric-based evaluation. Here's a condensed breakdown of what the transition actually required: